The problem is to evaluate
\(I = I(f) = \int f d\mu,\)
where $$ is a probability measure on a space \(\mathbb{M}\) and where \(f: \mathbb{M} \rightarrow \mathbb{R}\) is measurable. The Monte-Carlo estimate of \(I\) is
\(\frac{1}{n}\sum_{i=1}^n f(x_i), \qquad x_i \sim \mu.\)
When it is too difficult to sample \(\mu\), for instance, other estimates can be obtained. Suppose that \(\mu\) is absolutely continuous with respect to another probability measure \(\lambda\), and that the density of \(\mu\) with respect to \(\lambda\) is given by \(\rho\). Another unbiaised estimate of \(I\) is then
\(I_n(f) = \frac{1}{n}\sum_{i=1}^n f(y_i)\rho(y_i),\qquad y_i \sim \lambda.\)
This is the general framework of importance sampling, with the Monte-Carlo estimate recovered by taking \(\lambda = \mu\). An important question is the following.
How large should \(n\) be for \(I_n(f)\) to be close to \(I(f)\)?
An answer is given, under certain conditions, by Chatterjee and Diaconis (2015). Their main result can be interpreted as follows. If \(X \sim \mu\) and if \(\log \rho(X)\) is concentrated around its expected value \(L=\text{E}[\log \rho(X)]\), then a sample size of approximately \(n = e^{L}\) is both necessary and sufficient for \(I_n\) to be close to \(I\). The exact sample size needed depends on \(\|f\|_{L^2(\mu)}\) and on the tail behavior of \(\log\rho(X)\). I state below their theorem with a small modification.
Theorem 1. (Chatterjee and Diaconis, 2015) As above, let \(X \sim \mu\). For any \(a \gt; 0\) and \(n \in \mathbb{N}\),
\(\mathbb{E} |I_n(f) - I(f)| \le \|f\|_{L^2(\mu)}\left( \sqrt{a/n} + 2\sqrt{\mathbb{P} (\rho(X) \gt; a)} \right).\)
Conversely, for any \(\delta \in (0,1)\) and \(b \gt; 0\),
\(\mathbb{P}(1 - I_n(1) \le \delta) \le \frac{n}{b} + \frac{\mathbb{P}(\rho(X) \le b)}{1-\delta}.\)
Remark 1. Suppose \(\|f\|_{L^2(\mu)} \le 1\) and that \(\log\rho(X)\) is concentrated around \(L = \mathbb{E} \log\rho(X)\), meaning that for some \(t \gt; 0\) we have that \(\mathbb{P}(\log \rho(X) \gt; L+t/2)\) and \(\mathbb{P}(\log\rho(X) \lt; L-t/2)\) are both less than an arbitrary \(\varepsilon \gt; 0\). Then, taking \(n \geq e^{L+t}\) we find
$ |I_n(f) - I| e^{-t/4} + 2.$
However, if $n e^{L-t} $, we obtain
$ (1 - I_n(1) ) e^{-t/2} + 2 .$
meaning that there can be a high probability that \(I(1)\) and \(I_n(1)\) are not close.
Remark 2. Let \(\lambda = \mu\), so that \(\rho = 1\). In that case, \(\log\rho(X)\) only takes its expected value \(0\). The theorem yields
\(\mathbb{E} |I_n(f) - I(f)| \le \frac{\|f\|_{L^2(\mu)}}{\sqrt{n}}\)
and no useful bound on \(\mathbb{P}(1-I_n(1) \le \delta)\).
Comment. For the theorem to yield a sharp cutoff, it is necessary that \(L = \mathbb{E} \log\rho(X)\) be relatively large and that \(\log\rho(X)\) be highly concentrated around \(L\). The first condition is not aimed at in the practice of importance sampling. This difficulty contrasts with the broad claim that “a sample of size approximately \(e^{L}\) is necessary and sufficient for accurate estimation by importance sampling”. The result in conceptually interesting, but I’m not convinced that a sharp cutoff is common.
Example
I consider their example 1.4. Here \(\lambda\) is the exponential distribution of mean \(1\), \(\mu\) is the exponential distribution of mean 2, \(\rho(x) = e^{x/2}/2\) and \(f(x) = x\). Thus \(I(f) = 2\). We have \(L = \mathbb{E}\log\rho(X) = 1-\log(2) \approxeq 0.3\), meaning that the theorem yields no useful cutoff. Furthermore, \({}\mathbb{P}(\rho(X) \gt; a) = \tfrac{1}{2a}\) and \(\|f\|_{L^2(\mu)} = 2\). Optimizing the bound given by the theorem yields
\(\mathbb{E}|I_n(f)-2| \le \frac{4\sqrt{2}}{(2n)^{1/4}}.\)
The figure below shows \(100\) trajectories of \(I_k(f)\). The shaded area bounds the expected error.
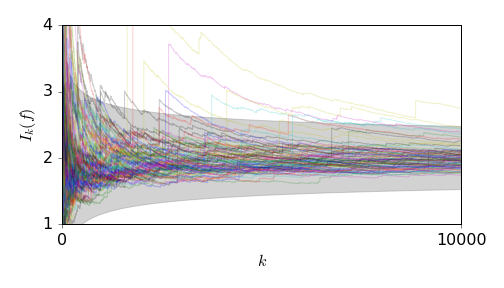
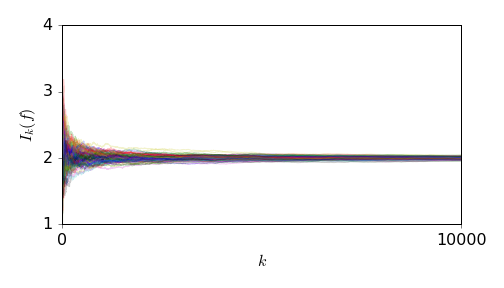
This next figure shows \(100\) trajectories for the Monte-Carlo estimate of \(2 = \int x d\mu\), taking \(\lambda = \mu\) and \(\rho = 1\). Here the theorem yields
\(\mathbb{E}|I_n(f)-2| \le \frac{2}{\sqrt{n}}.\)
References.
Chatterjee, S. and Diaconis, P. The Sample Size Required in Importance Sampling. https://arxiv.org/abs/1511.01437v2